Predictive Modeling in Clinical Trials: A Data-Backed Crystal Ball

In the business world, financial modeling has long been the go-to tool to predict the future performance of a company or investment. Now with the growing availability of big data, the pharmaceutical industry is increasingly turning to predictive modeling for a variety of tasks, from identifying new molecules for drug targets to forecasting clinical trial timelines.
For Mohanish Anand, Executive Director, Head of Study Optimization at Pfizer, predictive modeling is the bread and butter of what he does: calculating how long it will take to hit various milestones and complete a clinical trial.

In the journey of drug development, there is a lot at stake—patients are eagerly awaiting new medicines, years of research have occurred and massive amounts of clinical data need to be gathered for regulatory approval. Accurate timelines matter. “Our teams have to understand what they’re working towards,” says Anand. “The biggest job of my team is to put all of the data sets together, create project plans and forecasts that we call ‘scenarios,’ and present them to the larger team.”
From Sample Surveys to Big Data
In finance, the disclaimer “past performance does not necessarily indicate future results” is often used. However, Anand is confident that data from prior clinical trials, de-identified medical records, and insurance claims data, all used with stringent attention toward patient privacy, are useful in predicting future timelines for drug development. “In planning clinical trials, more often than not we get the projected timing right,” he says.
About a decade ago, the information-gathering that went into clinical trial design was more like a focus group. “We would sit down with experts, doctors and scientists who are highly experienced in the area, and get their input,” says Anand, who has worked in clinical development for nearly two decades. Another tool they’d rely on was the “feasibility questionnaire,” a survey sent to a sample of doctors to get an idea of how many patients with a particular condition would be able to participate in a trial. “The doctors would give us their estimate, but it would be their opinion. Now we are becoming more and more fact-based and looking to make sure that we have data behind the projections that we make about timelines and potential outcomes,” he says.
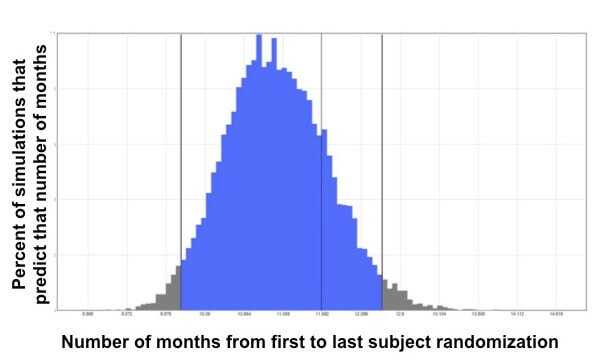
Thanks to the “big data” revolution, says Anand, they now have access to large de-identified data sets that can, for example, show how many anonymous patients within a certain age range across a wide geographic area have taken a certain medicine and have had positive results on a certain lab test. This type of information helps them predict how many patients may be available and eligible for a clinical trial. “All the tools, technologies and data sets that we have available now have allowed clinical trial planning to be more reliable,” he adds.
The Calculus of Patient Recruitment
Analyzing publicly available data also is an advantage, says Anand. Just recently, Anand and his team pulled data from public databases of all clinical trial information for a particular class of drugs. “When we looked at the real-world data, our clinicians realized that we could revise our trial design to improve recruitment rates and enroll far more patients, while still measuring our endpoint in a scientifically valid way,” says Anand. “And as a result of that, our trial is currently running on schedule. We’re on the right track.”